





Pipeline là một kỹ thuật mà trong đó các lệnh
được thực thi theo kiểu chồng lắp lên nhau.
-
Cách tiếp cận dùng kỹ thuật pipeline tiêu tốn ít thời gian hơn cho tất cả các
công việc hoàn tất bởi vì các công việc được thực hiện song song, vì vậy số
công việc hoàn thành trong một giờ sẽ nhiều hơn so với không pipeline.
- Chú ý, pipeline không làm giảm thời gian hoàn thành một công việc mà làm giảm
thời gian hoàn thành tổng số công việc (như trong ví dụ trên, thời gian cho người
A hoàn thành việc giặt khi áp dụng pipeline hay không pipeline đều là 2 giờ,
nhưng tổng số giờ cho 4 người A, B, C và D hoàn thành dùng pipeline giảm rất
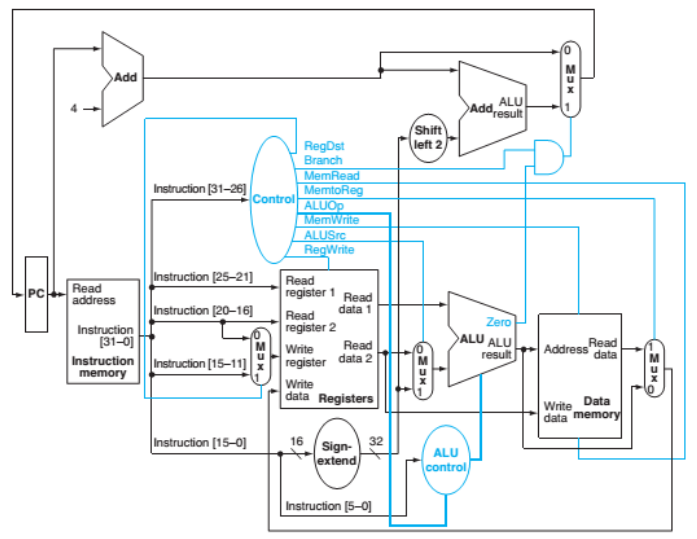
nhiều so với không pipeline)Khi thực thi, các lệnh MIPS được chia làm 5 công đoạn:
1. Nạp lệnh từ bộ nhớ (IF – instruction fetch)
2. Giải mã lệnh và đọc các thanh ghi cần thiết (MIPS cho phép đọc và giải mã đồng thời) (ID – instruction decode)
3. Thực thi các phép tính hoặc tính toán địa chỉ (EX – execute)
4. Truy xuất các toán hạng trong bộ nhớ (MEM – memory access)
5. Ghi kết quả cuối vào thanh ghi (WB – write back)
Vì vậy, MIPS pipeline trong chương này xem như có 5 công đoạn (còn gọi là pipeline 5 tầng)
Sự
tăng tốc của pipeline
v Trong trường hợp lý tưởng:
khi mà các công đoạn pipeline hoàn toàn bằng nhau thìthời gian giữa hai lệnh liên tiếp được thực thi trong pipeline bằng: thời gian giữa hai lệnh liên tiếp được thực thi trong pipeline bằng:
à Trong trường hợp lý tưởng, pipeline sẽ tăng tốc so với không pipeline với số lần đúng
bằng số tầng của pipeline.
bằng số tầng của pipeline.
v Trong thực tế: Các công đoạn thực tế không bằng nhau, việc áp dụng pipeline phải chọn
công đoạn dài nhất để làm một chu kỳ pipeline.
Speed-up ≈ Thời gian giữa hai lệnh liên tiếp không pipeline / Thời gian giữa hai lệnh liên tiếp pipeline
công đoạn dài nhất để làm một chu kỳ pipeline.
Speed-up ≈ Thời gian giữa hai lệnh liên tiếp không pipeline / Thời gian giữa hai lệnh liên tiếp pipeline
à Trong thực tế, pipeline sẽ tăng tốc so với không pipeline với số lần nhỏ hơn số tầng
của pipeline.
của pipeline.
Thời gian giữa hai lệnh liên tiếp không pipeline / Thời gian giữa hai lệnh liên tiếp pipeline
Lưu ý, pipeline tăng tốc so với không pipeline:
- Kỹ thuật pipeline không giúp giảm thời gian thực thi của từng lệnhriêng lẽ mà giúp giảm tổng thời gian thực thi của đoạn lệnh/chươngtrình chứa nhiều lệnh (từ đó giúp thời gian trung bình của mỗi lệnhgiảm)riêng lẽ mà giúp giảm tổng thời gian thực thi của đoạn lệnh/chươngtrình chứa nhiều lệnh (từ đó giúp thời gian trung bình của mỗi lệnhgiảm)
- Việc giúp giảm thời gian thực thi cho nhiều lệnh vô cùng quantrọng, vì các chương trình chạy trong thực tế thông thường lên đếnhàng tỉ lệnh.trọng, vì các chương trình chạy trong thực tế thông thường lên đếnhàng tỉ lệnh.
Các xung đột có thể xảy ra khi áp dụng
kỹ thuật pipeline (Pipeline Hazards):
Xung đột là trạng thái mà lệnh tiếp
theo không thể thực thi trong chu kỳ pipeline ngay sau đó (hoặc thực thi nhưng
sẽ cho ra kết quả sai), thường do một trong ba nguyên nhân sau:
Xung đột cấu trúc (Structural hazard): là khi một lệnh dự kiến không thể thực thi trong đúng chu kỳ pipeline của
nó do phần cứng cần không thể hỗ trợ.
Nói cách khác, xung đột cấu trúc xảy ra khi có hai lệnh cùng truy xuất vào một
tài nguyên phần cứng nào đó cùng một lúc.Xung đột dữ liệu (Data
hazard): là khi một lệnh dự kiến không thể thực thi
trong đúng chu kỳ pipeline của nó do dữ liệu mà lệnh này cần vẫn chưa sẵn sàng.Xung đột điều khiển (Control/Branch hazard): là khi một lệnh dự kiến không thể thực thi trong đúng chu kỳ pipeline của nó do lệnh nạp vào không phải là lệnh được cần. Xung đột này xảy ra trong trường hợp luồng thực thi chứa các lệnh nhảy
Cách giải quyết xung đột dữ liệu:
-
Cách 1: Chờ chu kỳ xung clock.
-
Cách 2: Kỹ thuật nhìn trước (forwarding hay bypassing)
+ Kỹ thuật nhìn
trước: một phương pháp giải quyết xung đột dữ liệu bằng đưa thêm vào các bộ đệm
phụ bên trong, các dữ liệu cần có thể được truy xuất từ bộ đệm này hơn là chờ đợi
đến khi nó sẵn sàng trong bộ nhớ hay trong thanh ghi.
+ Lưu ý, với lệnh lw và các lệnh có chức năng
tương tự, thông thường kết quả cuối của nó không phải khi hoàn tất công đoạn EX
mà là khi hoàn tất công đoạn MEM. (chờ 4 chu kỳ)
Kỹ thuật forwarding có thể hỗ trợ giải quyết xung đột
dữ liệu hiệu quả, tuy nhiên nó không thể ngăn chặn tất cả các trường hợp chu kỳ
rỗi.
+ Tóm lại, với kỹ thuật forwarding có:ALU-ALU forwarding hay EX-EX forwarding (hình 1)MEM-ALU forwarding hay MEM-EX forwarding (hình 2)

hình 1

hình 2
Đối với phần Pipelined trong KTMT, việc xảy ra xung dột là điều hoàn toàn có thể, nhưng cũng có giải quyết, có 2 chú ý với kỹ thuật cho phép gửi vượt trước : Forwarding và ko cho gửi Non - forwarding như sau
- Non - forwarding: khi có 2 lệnh ở các chu kỳ kế tiếp nhau sử dụng chung thanh ghi (1 lệnh đọc và 1 lệnh ghi) thì: Chỉ khi lệnh trước nó tới công đoạn WB (nửa đầu WB đã dc ghi) thì lệnh tiếp theo dc phép thực thi ở công đoạn ID (giải mã lệnh ở nửa sau ID)
=> Kết luận: chỉ cần chú ý đặt NOP sao cho WB của lệnh trước thẳng hàng với ID của lệnh kế tiếp (tham khảo thêm hình)
- Forwarding: với các lệnh thuộc kiểu R-Format (add, sub...) thì EX của lệnh trước cần thẳng hàng với ID của lệnh sau (đảm bảo EX sau khi cho KQ được truyền thẳng tới ALU lệnh sau nó),
lệnh LW thì MEM của lệnh trước thẳng hàng với ID của lệnh sau (đảm bảo sau khi đọc/ ghi DL ở công đoạn MEM xong mới dc truyền xuống ALU của lệnh kế tiếp)
Chia sẻ trên bỏ qua các lệnh ss nhảy như beq (vì vướng điều kiện tiên đoán) ^^
Bạn nào có kinh nghiệm làm bài ở dạng này có thể cmt chia sẻ với mọi người nhé ^^
p/s: lệnh SW ít xảy ra do theo trình tự code: lw để load DL từ ô nhớ ra thanh ghi, thực thi bằng lệnh add, sub... và cuối cùng lưu lại giá trị của thanh ghi này xuống bộ nhớ => sw đã là lệnh cuối và ko lệnh nào thực thi sau nó nữa ^^ (Đặng Thị Kim Luyến)





.png)
.png)
.png)


.png)
